A friend had a theory that photography, and therefore by extension c r o s s o a k is a window into my mental well being. So I did some digging which I'm capturing here (and which is in all probability a much bigger insight into my head...). If you have a similar theory, you might think the conclusion tells you quite a lot. If you don't it won't.
Getting the data
First off, let's grab some data from Wordpress, the blog platform that currently powers c r o s s o a k.
This gets a reference to wp which we can use to query wordpress, for example this code:
post_data={}# get pages in batches of 20offset=0increment=20whileTrue:posts=wp.call(GetPosts({'number':increment,'offset':offset}))iflen(posts)==0:break# no more posts returnedforpostinposts:post_data[post.id]={"title":post.title,"date":post.date.strftime("%Y%m%d"),"img_count":count_images(post)}offset=offset+increment
will get some basic data on all the posts in the blog. In the above count_images uses BeautifulSoup to parse post content to count img tags like this:
To analyse the content we'll use Pandas and Seaborn.
importjsonimportpandasaspdimportnumpyasnpimportseabornassnsimportmatplotlib.pyplotasplt# load JSON file with our Wordpress datawithopen('wp_data.json')asjson_data:d=json.load(json_data)# convert to a DataFramedf=pd.DataFrame(d)df=df.transpose()df.reset_index(inplace=True)df.rename(columns={'index':'id'},inplace=True)
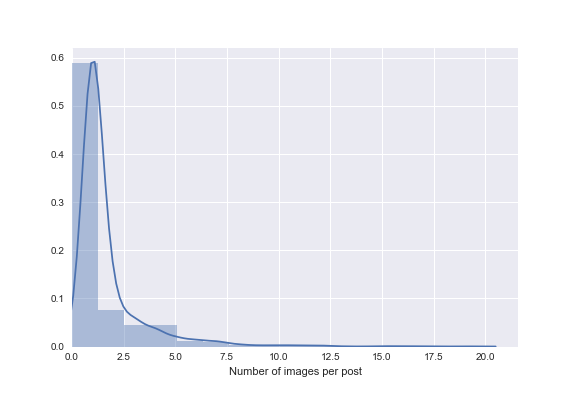
Which we can then use to visualize the distribution of the number of images per post.
sns.distplot(df.img_count,kde_kws={"bw":.5},bins=15)sns.plt.xlim(0,None)sns.plt.xlabel('Number of images per post')
Distribution of images (vertical axis) per post
To delve a bit data, we'll augment the data, breaking out the date with year, month, day and weekday and counting words and characters in the titles...
...and calculate summaries using groupby for counts of posts and the total number of images:
# get summarized viewsdf_imgs=df.groupby([df.year,df.month]).img_count.sum()df_posts=df.groupby([df.year,df.month]).id.count()df_imgs=pd.DataFrame(df_imgs)df_imgs.reset_index(inplace=True)df_posts=pd.DataFrame(df_posts)df_posts.reset_index(inplace=True)df_summary=pd.merge(df_imgs,df_posts,on=['month','year'])
Comparing the DataFrames for the original data imported from JSON in df:
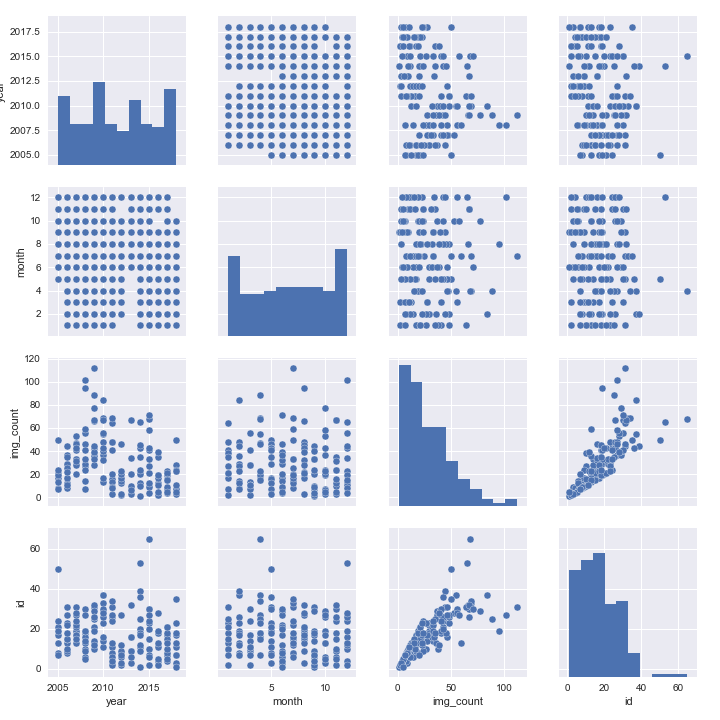
Using the summary data we can also explore correlations between fields with a pair plot:
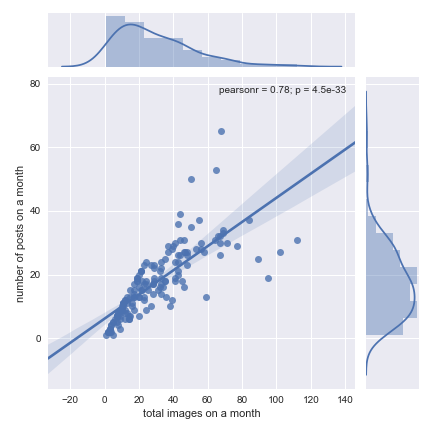
or look at the correlation between number of posts and number of images per month
jp=sns.jointplot(df_summary['img_count'],df_summary['id'],kind='reg')jp.set_axis_labels('total images on a month','number of posts on a month')
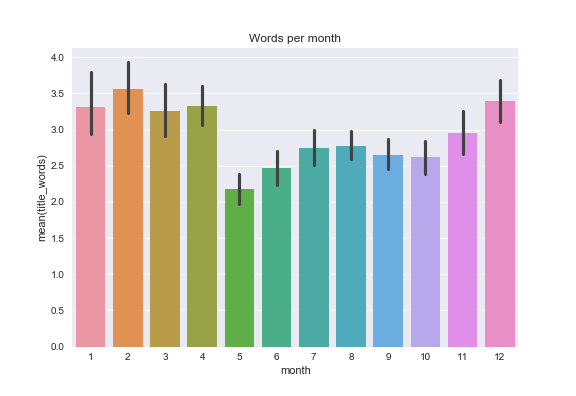
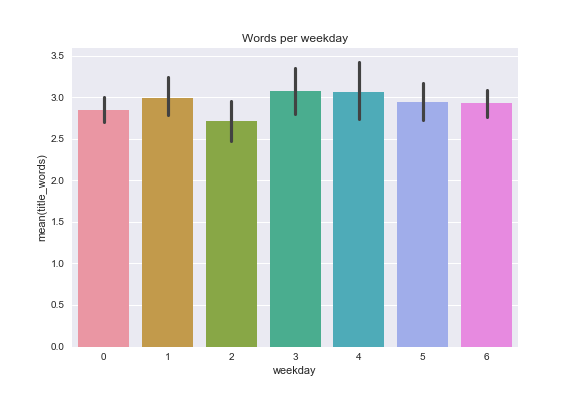
We can also play around with the words used in titles:
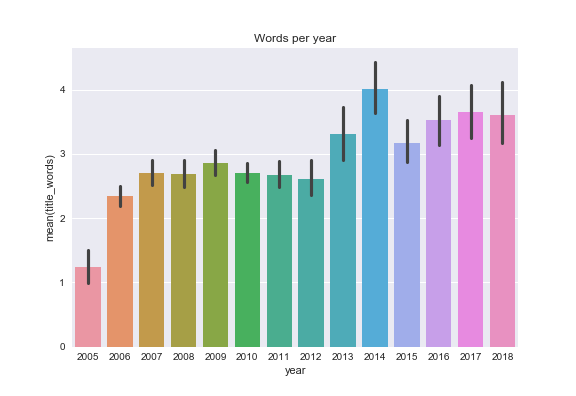
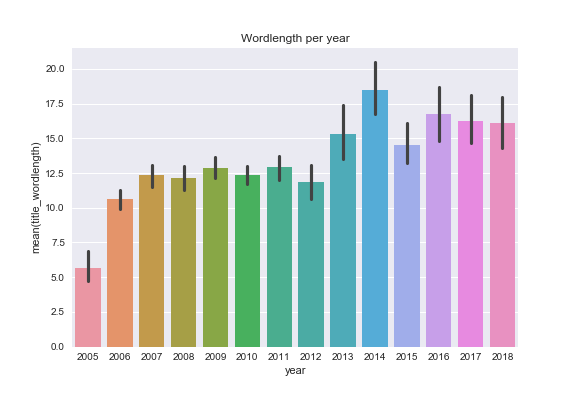
and also see if I used longer or shorter words in post titles over the years c r o s s o a k has been published
Conclusions
So what have we learnt from the excursion into the data lurking behind c r o s s o a k?
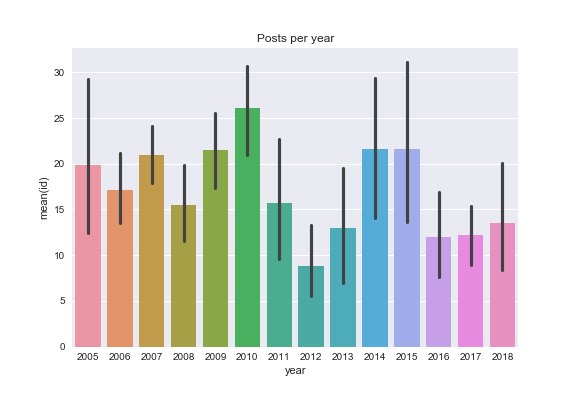
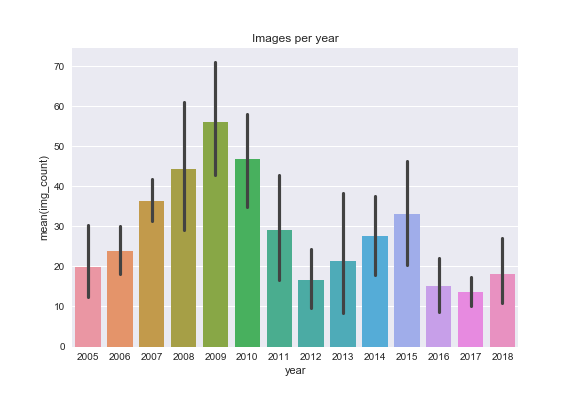
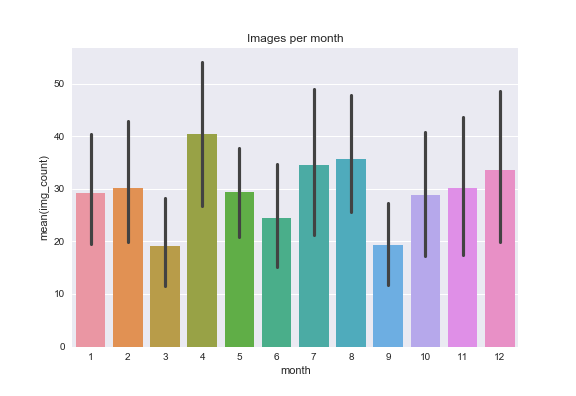
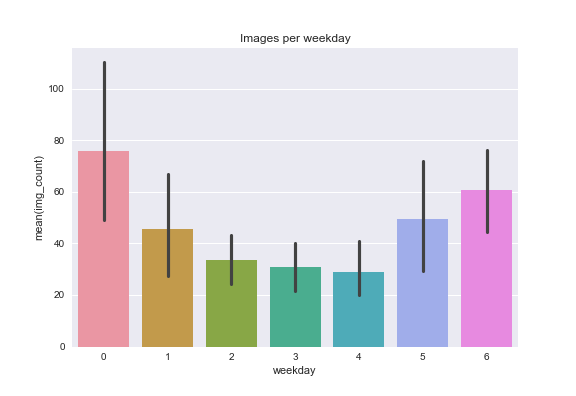
2012 was a low year for both posts and images posted. The number of posts recovered slightly in 2016-2018 but not the number of images (more posts have only one image on average).
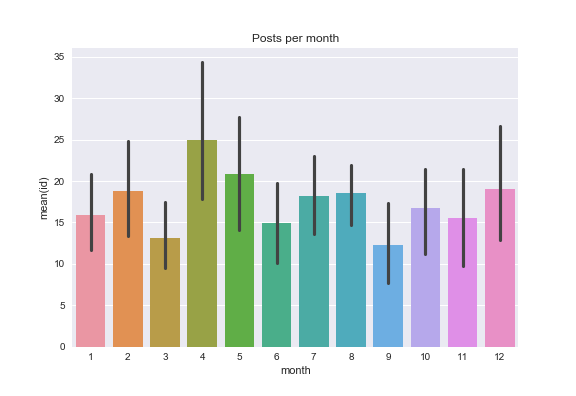
April is when I post most
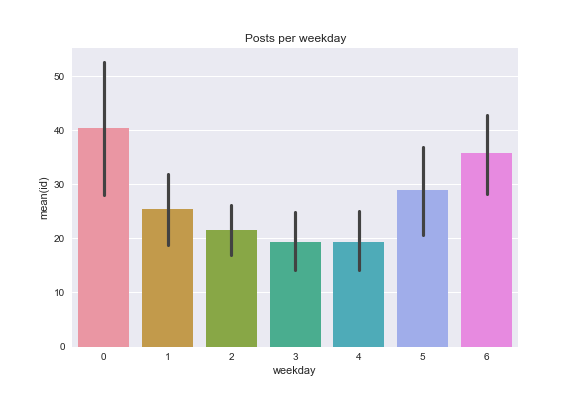
I post on weekend's and Fridays more than midweek
I use the fewest words in post titles in May
Over the years I've used more words and longer words in post titles
This is the kind of thing you do on a dark autumn evening in the northern hemisphere. Apparently it's why Scandinavia has so many tech start-ups (relative to population).
C r o s s o a k is a photo blog that goes back to Lost Something in Cromer in May 2005. It's really a photo journal. Or a log of things illustrated by photos that's available on the web, a web log. It's been through a couple of iterations since starting out on Blogger with snaps from a Sony DSC-V1 processed in Picasa.
For the longest time the core workflow was:
Take photo
Import to Adobe Lightroom
Tweak photo
Upload to Flickr
Draft new post in Wordpress
Publish
That had a couple of downsides. First, it's quite manual. Second, it's hard to do when travelling light. This meant that posts for Crossoak tended to batch up waiting for some time for me to publish.
There's an adage that the Best camera is the one you have with you. Around 2010 (for many reasons, not all of them photography related), the camera I had with me was often the one glued into the back of a mobile phone. That was okay for uploading pictures, there was an embarrassment of riches for sync'ing photos from phones, but publishing and sharing in something like a blog post was still challenging. In the real, non-geek, world that's why something like Instagram happens. Someone, somewhere, figures out how to solve a pain point that it turns out lots of other people also have. Turns out that included me too. So I had another workflow that went:
Take photo
Share on Instagram
But now I had posts on Crossoak and Instagram (/sadface) and I didn't really want to republish that were already on instagram to Crossoak manually because that makes even more work.
Enter IFFF. IFTTT is a webservice that lets you create recipes that combine actions from other webservices. With IFTTT the Instagram workflow becomes
Take photo
Share on Instagram
Automatically!!!
Check if Instagram post has the #blog tag, if it does then...
Publish the instagram post to Crossoak too
This worked really well, so well that the majority of the Crossoak posts over the last 12 months have been via instagram.
That was until stuff started to break.
The problem was that posts published by IFTTT used Instagram links that changed, resulting in large parts of Crossoak to experience broken image syndrome. Not a good look when you're a photo blog. Especially not when any text you include is frequently so cryptic as to cause confusion even with those that were featured in the accompanying photographs.
Fortunately, there was a straight-forward fix. When creating the IFTTT recipe to post from Instagram, I also created one to upload the same image to Flickr. This meant I had copies of the broken images (or all except one) on Flickr. Fixing was possible, but that was a lot of links. I was looking at all the time saved over the years in my clever hack to the publication workflow being eaten up by the cost of fixing. Douglas Coupland smiles.
Fixing Bit Rot
Programmatically, an automated fix was relatively trivial. Iterate through the posts on Crossoak; identify posts published from Instagram; search Flickr for the corresponding photo; update the Crossoak post, replacing Instagram with the corresponding link to Flickr. Simples.
First, iterate through posts using the python-wordpress-xmlrpclibrary:
fromwordpress_xmlrpcimportClientfromwordpress_xmlrpc.methods.postsimportGetPostsendpoint=blog_url+'/xmlrpc.php'wp=Client(enpoint,auth_user,auth_password)offset=0increment=20whileTrue:posts=wp.call(GetPosts({'number':increment,'offset':offset}))iflen(posts)==0:break# no more posts returnedforpostinposts:update_if_instagram(post)offset=offset+increment
To identify Instagram posts I considered looking for the Instagram tag (which the IFTTT recipe created) but instead I opted for searching the <img> tag src attribute for the magic text with Beautiful Soup:
The tricky bit was finding the corresponding Flickr photos. Flickr has a lovely API (here's the API explorer for search) which the python-flickr-apilibrary nicely wraps, so I can search with something like:
There were two snags however. First, the text attribute is a fuzzy search, and my Instagram-generated post titles are far from unique. This was mitigated by scoping the search to +/- a day of the Wordpress post:
But a second problem was that Flickr wasn't returning everything I thought it should. In many cases I could manually browse to the right image, but the API wasn't returning it based on the text search. So I flipped the search logic and used the Flickr API to return all photos in the right time range and then let Python's string search find the match:
Wow. iOS is fussy about MPEG4 encoding. Stuff that worked fine as HTML5 video sources in Chrome and Safari on a Mac failed to load in various i-devices. In the end I re-encoded using FFMPEG and:
Windows Server has this neat feature: Storage Pools. In a nutshell it separates the logical storage from physical devices. I use it to make two physical hard drives appear as one logical disk. Anything saved to the pool is mirrored to both disks. In theory, this means that a failure of one physical drive won't loose any data since a copy is available on the second.
Last week I had a drive failure. It wasn't either of the drives in the storage pool. Instead the system drive (a third drive hosting the OS) had failed.
I think it took me 40 minutes to be up and running enough to validate the data was okay.
Install replacement system disk
Reinstall Windows Server 2012 R2
Reconnect two physical disks hosting the storage pool
Trawl the interwebs for details of how to reattached the storage pool
Job done (except for the reboots and updates and reboots and updates thing...).
One trick, Windows server doesn't automatically mount a newly attached pool on reboot. Here'e the PowerShell rune to chnage that: